Innovative AI-Powered Document Processing in the Banking Sector
Banks process thousands of documents every day – often still manually. Modern AI-powered document processing, using OCR, natural language processing and computer vision, transforms PDFs into structured data sets, thereby delivering speed, efficiency and audit assurance.


- Why banks have a document problem
- Three benefits that make all the difference
- The four-level model of AI-powered document processing
- The technology mix: OCR, VLMs and computer vision
- Six quality gates for a detection rate of over 95 per cent
- Automatic schema recognition: a game-changer for input management
- Platform architecture: the EU cloud and data sovereignty
- Practical examples: From construction financing to management accounting
- Conclusion: AI-powered document processing is becoming a strategic capability
Included in this collection:
Open collection
Digital Omnibus on Artificial Intelligence: What banks need to know

After Claude Mythos: How banks can ensure their AI resilience

AI Usage in Europe: Why the Nordics Have the Edge

Claude Mythos in Banking: AI on the Way to Information Security

Innovative AI-Powered Document Processing in the Banking Sector

Artificial Intelligence in Treasury – from periodic financial reporting to a continuous management function
How to ensure the long-term success of AI projects in banking

The Year of Quantum Computing: 2026 – Opportunities, Risks and the Path to Quantum Security

Architecture of Trust: the New Operating System for Internal Auditing

Treasury AI Is Not Trading AI: Why Banks Need a New Control Architecture
Why banks have a document problem
No other type of business handles as many documents as a bank. Energy performance certificates, land registry extracts, payslips, annual accounts, sales contracts, balance sheets, fund reports: the list is long, the formats are varied, and the quality is inconsistent. In practice, this has led to the same pattern for years: a PDF is filed away, three clerks look at it one after the other, type out the same data and enter it into their respective systems. This costs time, ties up resources and creates sources of error.
This shows that the reality of document processing differs significantly from the ideal scenario. Whilst banks require structured, standardised and machine-readable data sets, they work with scanned documents, inconsistent layouts, handwritten additions and documents with complex content. The gap between aspiration and reality is vast.
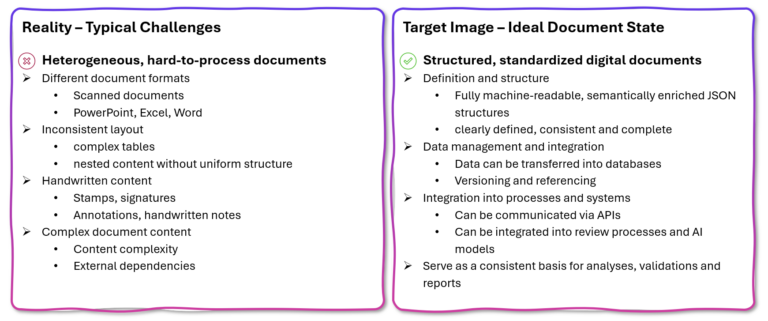
Figure 1: AI-powered document processing bridges the gap between unstructured paper documents and structured datasets
Three benefits that make all the difference
Why should a bank invest in AI-powered document processing? The answer lies in three specific benefits.
Speed as a competitive advantage: If a mortgage customer submits documents and then has to wait two weeks for them to be passed back and forth between sales and back-office departments, this is a clear disadvantage compared to faster competitors. Those who check, classify and digitise documents immediately upon receipt can provide feedback to the customer within seconds.
Efficiency through data records rather than PDFs: A digitised document exists in the system as a structured data record, not as a static PDF that has to be opened manually time and again. This eliminates redundant work steps and makes information usable across systems.
Alleviating the skills shortage: Teams that are already “swamped” benefit when knowledge from documents is automatically transferred into IT systems. AI does not replace skilled staff, but it does relieve them of repetitive tasks.
The four-level model of AI-powered document processing
A key structuring principle for AI-powered document processing in the banking sector is the four-level model. It helps organisations to accurately assess their own requirements and select the appropriate level of solution depth.

Figure 2: Four levels of AI-powered document processing: from initial screening to fraud prevention
Level 1: Correctness check. The first question is: Is the submitted document the right one at all? Is it legible? Is the quality sufficient? In the past, this classification required rule-based input management systems. Today, language models perform this task more quickly and cost-effectively. The key advantage is that incorrect or inadequate documents are identified immediately upon receipt, rather than only during back-office processing.
Level 2: Digitisation. Here, the document is converted into a structured data set. Tables, fields and sections are identified, extracted and transformed into the target format (typically JSON). The result: all downstream processes work with data rather than PDFs.
Level 3: Content validation. The top tier. The data record is subject-matter checked, scored against the bank’s guidelines and assessed for content. This creates, for the first time, a consistent view across departmental boundaries. In mortgage lending, this means: Sales can see what back-office is likely to find, and vice versa.
Level 4: Fraud detection. An optional, separate component for institutions with a corresponding risk profile. It searches for pixel discrepancies, copied numbers and metadata anomalies in manipulated PDFs. Note: This is not a standard feature, but a targeted tool for specific business models.
The technology mix: OCR, VLMs and computer vision
A common mistake in practice: a document is fed into a single language model – with the expectation that it will handle everything. But this does not work reliably. Quality is achieved through a phased combination of three technologies.
OCR (optical character recognition) forms the basis. It recognises rough structures within the document, extracts text from simple sections and identifies handwritten content. Anything that is structurally straightforward is processed here reliably and cost-effectively. More complex elements are passed on to the next stage.
Visual Language Models (VLMs) represent the key technological advance of recent months. Multimodal models understand content within a visual context: tables spanning multiple pages, forms with nested structures, and diagrams in annual reports. Just one or two years ago, processing such content was not reliably possible. Today, for the first time, banks can process documents holistically, including their graphical components.
Computer Vision prepares difficult document passages for AI processing. It optimises images by adjusting contrast, cleans up backgrounds and segments the layout into header, text area and footer. The result often looks unusual to humans, but enables the AI models to achieve significantly better results.
Six quality gates for a recognition rate of over 95 per cent
Quality assurance for productive AI-based document processing is carried out via six sequential quality gates:
- Preprocessing,
- Layout analysis,
- Template matching,
- Named entity recognition,
- Plausibility check and
- Majority voting.
Each stage checks and refines the result of the previous one.
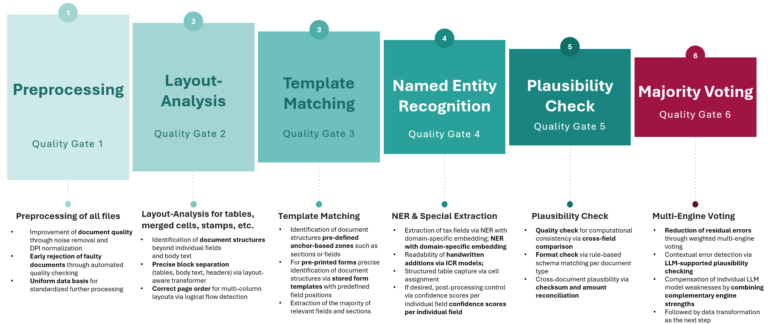
Figure 3: Six quality gates ensure that the recognition rate of the AI-powered document processing system remains above 95 per cent
Particularly noteworthy: the final majority voting process combines several AI models to reduce residual errors. By combining the complementary strengths of the engines, the weaknesses of individual models are offset. LLM-based plausibility checks and cross-field comparisons ensure computational consistency.
Automatic schema recognition: a game-changer for input management
Another technological innovation deserves special attention. Previously, every document type required a predefined schema: the bank had to specify in advance which fields were expected in which document type. Modern AI can generate these schemas itself.
A good example of this is a Lufthansa Express bus ticket, a document type previously unknown to the system. The AI independently recognises the relevant data fields (Issue Date, Total Price, Passenger Name, Company Details) and extracts them correctly. This represents a significant step forward for banks’ input management: even unknown document types can be processed immediately into structured data records. This brings us closer to dark processing.
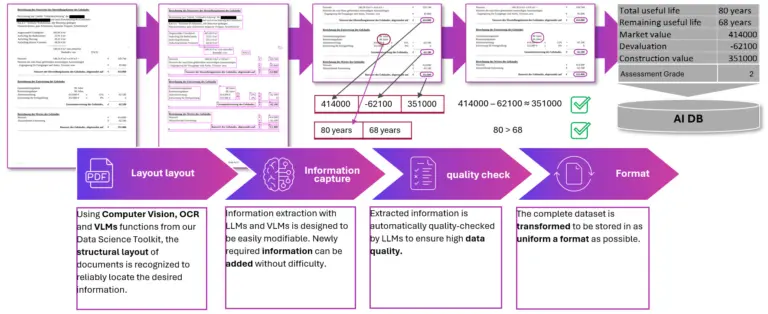
Figure 4: From paper document to structured data set: AI-powered document processing in four steps
Platform Architecture: EU Cloud and Data Sovereignty
One aspect that is always a key consideration in discussions with banking decision-makers is: where is the data processed? The msg GenAI platform is based on a microservices architecture, hosted on AWS in Frankfurt am Main (alternatively Azure or Stackit). Two components are deliberately decoupled from one another: service operation and language model operation. This ensures maximum sovereignty vis-à-vis individual providers.
Processing is data-minimal: data is temporarily stored in secure cloud storage and deleted immediately after successful processing. The commissioned data processing complies with standard banking practices.

Practical examples: From construction financing to management accounting
The range of productive use cases is considerable. A major German savings bank is implementing a complete mortgage application process on a single platform. As soon as customers upload a land registry extract, they receive immediate feedback on whether there are any entries in Section 2, and if the outcome is positive, they are routed directly to a VIP line.
Development banks are digitising tax documents, instalment loan providers are processing scans of poor quality (mobile phone photos taken in poor lighting conditions) and asset managers are extracting risk metrics from fund reports. In the controlling department, automated invoice processing is underway, featuring account allocation suggestions and order assignment.
Conclusion: AI document processing is becoming a strategic capability
AI document processing has crossed a threshold in recent months: visual language models, more powerful OCR and computer vision are, for the first time, enabling end-to-end processing, whether dealing with structured printouts or blurry mobile phone photos. For decision-makers in banks, this presents three courses of action:
- Quick win: Automate accuracy checks upon document receipt. Low effort, immediate impact on processing times.
- Core project: Digitisation of the highest-volume document types (payslips, energy performance certificates, land registers) with structured data transfer to downstream systems.
- Strategic differentiation: Content validation as a technical preliminary check that bridges silos and delivers genuine speed to customers.
The technology is mature. The question is no longer whether, but to what extent banks will automate their document processes.





