Innovative KI-Dokumentenverarbeitung im Banking
Banken verarbeiten täglich Tausende Dokumente - oftmals noch manuell. Moderne KI-Dokumentenverarbeitung mit OCR, visuellen Sprachmodellen und Computer Vision verwandelt PDFs in strukturierte Datensätze und schafft so Geschwindigkeit, Effizienz und Prüfsicherheit.


- Warum Banken ein Dokumentenproblem haben
- Drei Mehrwerte, die den Unterschied machen
- Das Vier-Ebenen-Modell der KI-Dokumentenverarbeitung
- Der Technologie-Mix: OCR, VLMs und Computer Vision
- Sechs Quality Gates für über 95 Prozent Erkennungsquote
- Automatische Schema-Erkennung: Ein Gamechanger für das Input-Management
- Plattform-Architektur: EU-Cloud und Datensouveränität
- Praxisbeispiele: Von der Baufinanzierung bis zum Controlling
- Fazit: KI-Dokumentenverarbeitung wird zur strategischen Fähigkeit
In dieser Collection enthalten:
Collection öffnen
banKIng³ - Folge 33: Kosten, Modellwahl und Governance: Wie Banken ihre KI-Infrastruktur wählen

Robust durch eine schwache Marktphase: Wie mit Agentic Operations natürliche Fluktuation in eine variable Kostenstruktur transformiert werden kann

Souveräne KI in Banken
banKIng³ - Folge 32: Vom Antragsstau zur Echtzeit: Wie KI Massengeschäft und Boutique gleichzeitig löst

Digital Omnibus on AI: Was Banken jetzt wissen müssen

Nach Claude Mythos: Wie Banken ihre KI-Resilienz sicherstellen können
banKIng³ - Folge 31: Volle Sinne, leere Use Cases: Warum KI-Strategie mehr braucht
banKIng³ - Folge 30: Revolution in der Revision: KI, DORA und der Weg zur 100-Prozent-Prüfung
banKIng³ - Folge 29: Souveränität, Sicherheit, Systeme – Warum Banken jetzt handeln müssen

KI-Nutzung Deutschland: Warum die Nordics im Vorteil sind
Warum Banken ein Dokumentenproblem haben
Kein Unternehmenstyp arbeitet mit so vielen Dokumenten wie eine Bank. Energieausweise, Grundbuchsauszüge, Gehaltsabrechnungen, Jahresabschlüsse, Kaufverträge, Bilanzen, Fondsberichte: Die Liste ist lang, die Formate sind heterogen, die Qualität ist schwankend. In der Praxis führt das seit Jahren zu demselben Muster: Ein PDF wird abgelegt, drei Sachbearbeitende schauen nacheinander hinein, tippen dieselben Daten ab und geben sie in ihre jeweiligen Systeme ein. Das kostet Zeit, bindet Kapazitäten und erzeugt Fehlerquellen.
Das zeigt: Die Realität in der Dokumentenverarbeitung weicht erheblich vom Zielbild ab. Während Banken strukturierte, standardisierte und maschinenlesbare Datensätze benötigen, arbeiten sie mit eingescannten Dokumenten, uneinheitlichen Layouts, handschriftlichen Ergänzungen und inhaltlich komplexen Unterlagen. Die Lücke zwischen Wunsch und Wirklichkeit ist groß.
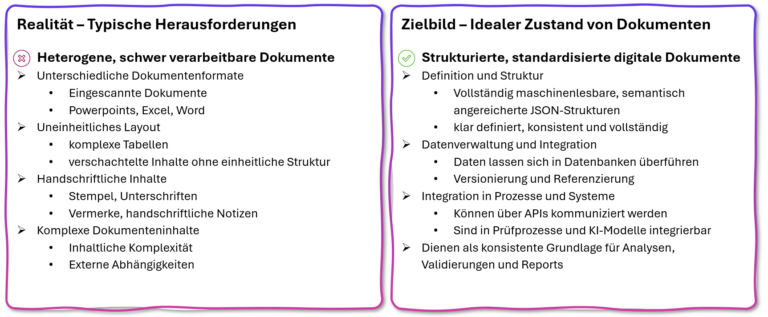
Abbildung 1: KI-Dokumentenverarbeitung schließt die Lücke zwischen heterogenen Papierdokumenten und strukturierten Datensätzen
Drei Mehrwerte, die den Unterschied machen
Warum sollte eine Bank in eine KI-Dokumentenverarbeitung investieren? Die Antwort liegt in drei konkreten Mehrwerten.
Geschwindigkeit als Wettbewerbsfaktor: Wenn ein Baufinanzierungskunde Unterlagen einreicht und anschließend zwei Wochen warten muss, bis die Dokumente zwischen Vertrieb und Marktfolge hin- und hergereicht wurden, ist das ein klarer Nachteil gegenüber schnelleren Wettbewerbern. Wer Dokumente sofort beim Eingang prüft, klassifiziert und digitalisiert, kann dem Kunden innerhalb von Sekunden Rückmeldung geben.
Effizienz durch Datensätze statt PDFs: Ein digitalisiertes Dokument lebt als strukturierter Datensatz im System, nicht als statisches PDF, das immer wieder manuell geöffnet werden muss. Das eliminiert redundante Arbeitsschritte und macht Informationen systemübergreifend nutzbar.
Fachkräftemangel entschärfen: Teams, die schon „unter Wasser stehen“, profitieren davon, wenn das Wissen aus Dokumenten automatisiert in IT-Systeme überführt wird. Die KI ersetzt keine Fachkräfte, entlastet sie aber bei repetitiven Tätigkeiten.
Das Vier-Ebenen-Modell der KI-Dokumentenverarbeitung
Ein zentrales Strukturierungsprinzip für die KI-Dokumentenverarbeitung im Banking ist das Vier-Ebenen-Modell. Es hilft, den eigenen Bedarf präzise einzuordnen und die passende Lösungstiefe zu wählen.

Abbildung 2: Vier Ebenen der KI-Dokumentenverarbeitung: Vom Eingangscheck bis zur Betrugsprävention

Ebene 1: Korrektheitsprüfung. Die erste Frage lautet: Ist das eingereichte Dokument überhaupt das richtige? Ist es lesbar? Ist die Qualität ausreichend? Früher erforderte diese Klassifizierung regelbasierte Input-Management-Systeme. Heute übernehmen Sprachmodelle diese Aufgabe schneller und kostengünstiger. Der entscheidende Vorteil: Fehlerhafte oder unzureichende Dokumente werden direkt beim Eingang erkannt und nicht erst in der Marktfolge.
Ebene 2: Digitalisierung. Hier wird das Dokument in einen strukturierten Datensatz verwandelt. Tabellen, Felder, Abschnitte werden identifiziert, extrahiert und in das Zielformat (typischerweise JSON) transformiert. Das Ergebnis: Alle nachgelagerten Prozesse arbeiten mit Daten statt mit PDFs.
Ebene 3: Inhaltliche Validierung. Die Königsklasse. Der Datensatz wird fachlich geprüft, gegen Richtlinien der Bank gescort und inhaltlich bewertet. Das schafft erstmals eine einheitliche Sicht über Abteilungsgrenzen hinweg. In der Baufinanzierung bedeutet das: Der Vertrieb sieht, was die Marktfolge voraussichtlich finden wird und umgekehrt.
Ebene 4: Fraud-Prüfung. Eine optionale, separate Komponente für Institute mit entsprechendem Risikoprofil. Sie sucht nach Pixelabweichungen, kopierten Zahlen und Metadaten-Anomalien in manipulierten PDFs. Anmerkung: Dies ist kein Standard, sondern ein gezieltes Werkzeug für bestimmte Geschäftsmodelle.
Der Technologie-Mix: OCR, VLMs und Computer Vision
Ein häufiger Fehler in der Praxis: Ein Dokument wird in ein einzelnes Sprachmodell geladen – mit der Erwartung, dass dieses alles erledigt. Doch das funktioniert nicht zuverlässig. Die Qualität entsteht durch einen gestaffelten Mix aus drei Technologien.
OCR (Texterkennung) bildet die Basis. Sie erkennt grobe Strukturen im Dokument, extrahiert Text aus einfachen Abschnitten und identifiziert handschriftliche Inhalte. Alles, was strukturell unkompliziert ist, wird hier bereits zuverlässig und kostengünstig verarbeitet. Komplexere Elemente werden an die nächste Stufe ausgesteuert.
Visuelle Sprachmodelle (VLMs) sind der entscheidende technologische Fortschritt der letzten Monate. Multimodale Modelle verstehen Inhalte im visuellen Kontext: Tabellen, die über mehrere Seiten laufen, Formulare mit verschachtelten Strukturen, Diagramme in Geschäftsberichten. Noch vor ein bis zwei Jahren war eine Verarbeitung solcher Inhalte nicht zuverlässig möglich. Heute können Banken erstmals Dokumente ganzheitlich verarbeiten, einschließlich ihrer grafischen Bestandteile.
Computer Vision bereitet schwierige Dokumentenpassagen für die KI-Verarbeitung auf. Sie optimiert Bilder durch Kontrastanpassung, bereinigt Hintergründe und segmentiert das Layout in Kopfzeile, Textbereich und Fußzeile. Das Ergebnis sieht für Menschen oft ungewöhnlich aus, ermöglicht aber den KI-Modellen signifikant bessere Ergebnisse.
Sechs Quality Gates für über 95 Prozent Erkennungsquote
Die Qualitätssicherung produktiver KI-Dokumentenverarbeitung erfolgt über sechs gestaffelte Quality Gates:
- Preprocessing,
- Layout-Analyse,
- Template Matching,
- Named Entity Recognition,
- Plausibilitätsprüfung und
- Majority Voting.
Jede Stufe überprüft und verfeinert das Ergebnis der vorherigen.
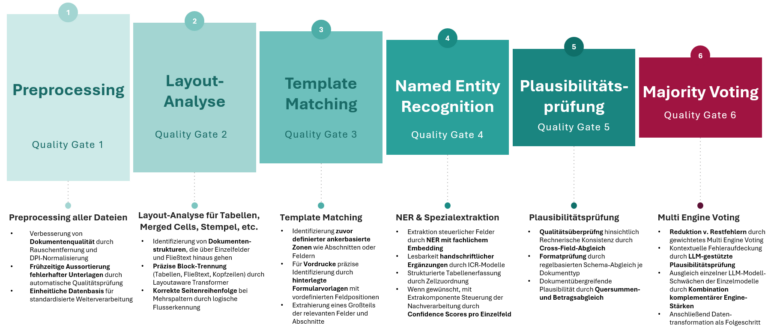
Abbildung 3: Sechs Quality Gates sichern die Erkennungsquote der KI-Dokumentenverarbeitung auf über 95 Prozent
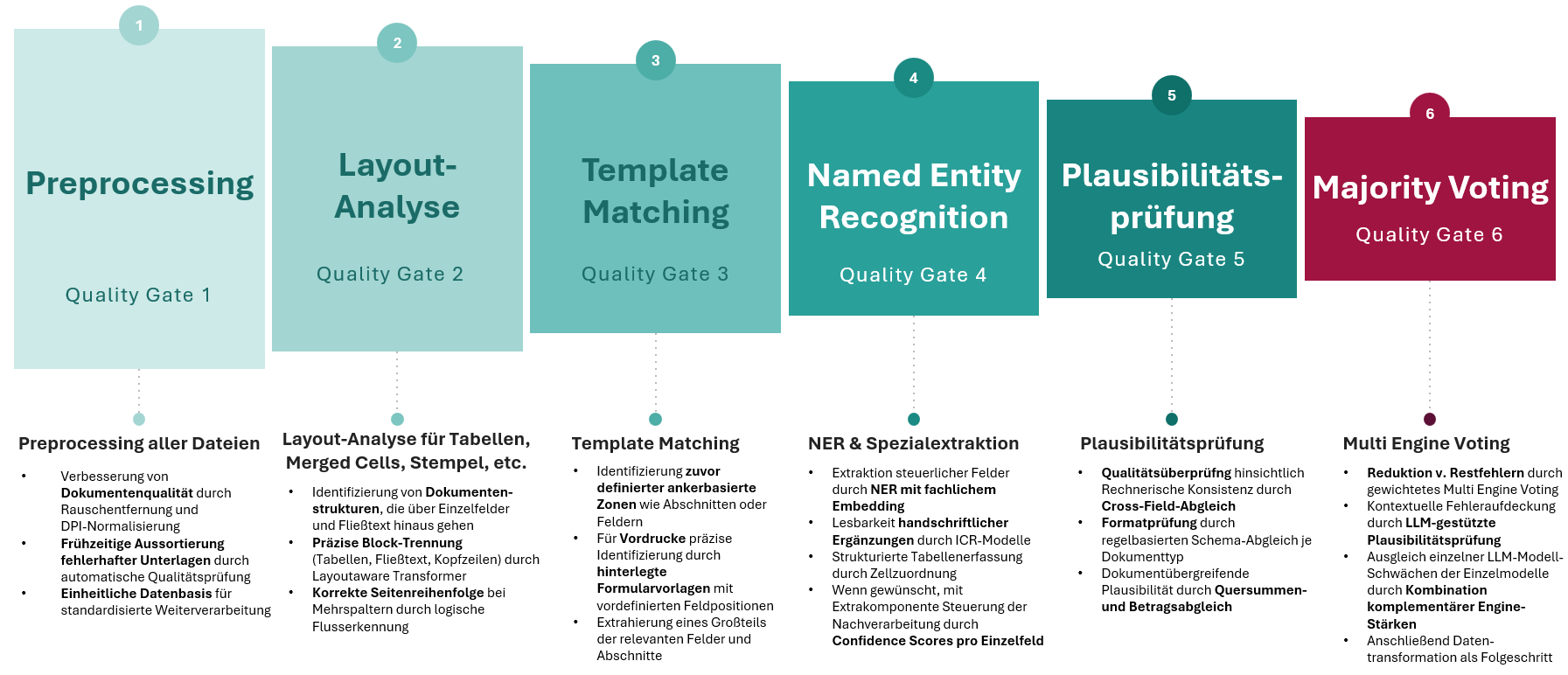
Besonders bemerkenswert: Das abschließende Majority Voting kombiniert mehrere KI-Modelle, um Restfehler zu reduzieren. Durch die Kombination komplementärer Engine-Stärken werden Schwächen einzelner Modelle ausgeglichen. LLM-gestützte Plausibilitätsprüfung und Cross-Field-Abgleich sorgen für rechnerische Konsistenz.
Automatische Schema-Erkennung: Ein Gamechanger für das Input-Management
Eine weitere technologische Neuerung verdient besondere Aufmerksamkeit. Bisher brauchte jede Dokumentenart ein vordefiniertes Schema: Die Bank musste vorab festlegen, welche Felder in welchem Dokumententyp erwartet werden. Moderne KI kann diese Schemata selbst generieren.
Ein gutes Beispiel dafür ist ein Lufthansa-Express-Bus-Ticket, ein Dokumententyp, der dem System zuvor nicht bekannt war. Die KI erkennt selbstständig die relevanten Datenfelder (Issue Date, Total Price, Passenger Name, Company Details) und extrahiert sie korrekt. Für das Input-Management von Banken ist das ein erheblicher Fortschritt: Auch unbekannte Dokumententypen können sofort zu strukturierten Datensätzen verarbeitet werden. Die Dunkelverarbeitung rückt damit näher.
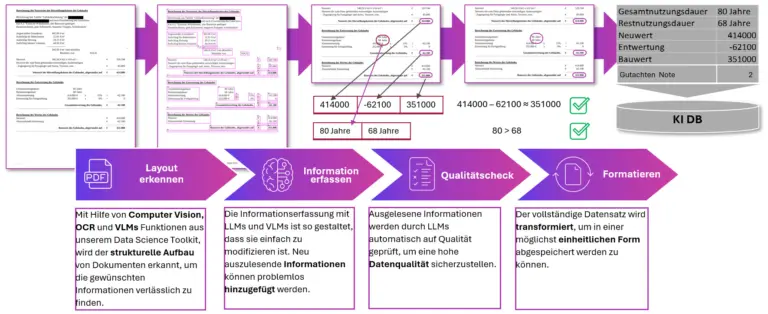
Abbildung 4: Vom Papierdokument zum strukturierten Datensatz: KI-Dokumentenverarbeitung in vier Schritten
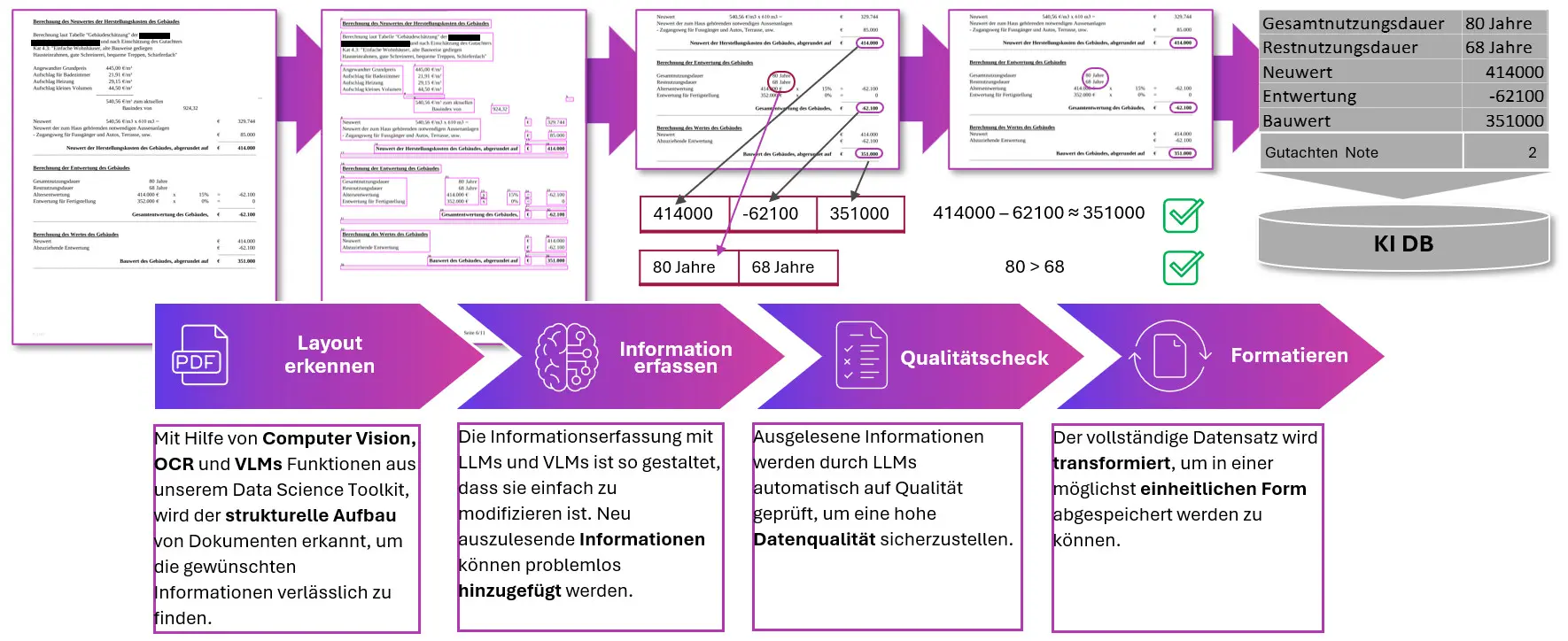
Plattform-Architektur: EU-Cloud und Datensouveränität
Ein Aspekt, der in der Diskussion mit Bankentscheidenden immer relevant ist: Wo laufen die Daten? Die msg-GenAI-Plattform basiert auf einer Microservices-Architektur, gehostet auf AWS in Frankfurt a. M. (alternativ Azure oder Stackit). Zwei Komponenten sind bewusst voneinander entkoppelt: der Service-Betrieb und der Sprachmodell-Betrieb. Das gewährleistet maximale Souveränität gegenüber einzelnen Anbietern.
Die Verarbeitung erfolgt datensparsam: Es erfolgt eine temporäre Speicherung in sicherem Cloudspeicher mit sofortiger Löschung nach erfolgreicher Verarbeitung. Die Auftragsdatenverarbeitung entspricht banküblichen Standards.

Praxisbeispiele: Von der Baufinanzierung bis zum Controlling
Die Bandbreite produktiver Einsatzszenarien ist beträchtlich. Eine große deutsche Sparkasse setzt eine vollständige Baufinanzierungs-Antragsstrecke auf einer Plattform um. Kunden erhalten bereits beim Upload eines Grundbuchauszugs eine sofortige Rückmeldung, ob Einträge in Abteilung 2 vorliegen, und werden bei positiver Prognose direkt auf eine VIP-Linie geroutet.
Förderbanken digitalisieren Steuerunterlagen, Ratenkreditanbieter verarbeiten qualitativ schwierige Scans (Handyfotos bei schlechten Lichtverhältnissen) und Asset Manager extrahieren Risikokennzahlen aus Fondsberichten. Im Controlling-Bereich läuft die automatisierte Rechnungsverarbeitung mit Kontierungsvorschlägen und Auftragszuordnung.
Fazit: KI-Dokumentenverarbeitung wird zur strategischen Fähigkeit
Die KI-Dokumentenverarbeitung hat in den letzten Monaten eine Schwelle überschritten: visuelle Sprachmodelle, leistungsfähigere OCR und Computer Vision ermöglichen erstmals eine ganzheitliche Verarbeitung, egal ob strukturierter Ausdruck oder verwackeltes Handyfoto. Für Entscheiderinnen und Entscheider in Banken ergeben sich daraus drei Handlungsoptionen:
- Quick Win: Korrektheitsprüfung beim Dokumenteneingang automatisieren. Geringer Aufwand, sofortige Wirkung auf Durchlaufzeiten.
- Kernprojekt: Digitalisierung der volumenstärksten Dokumententypen (Gehaltsabrechnungen, Energieausweise, Grundbücher) mit strukturierter Datenübergabe an Folgesysteme.
- Strategische Differenzierung: Inhaltliche Validierung als fachliche Vorprüfung, die Silos überbrückt und Kunden echte Geschwindigkeit liefert.
Die Technologie ist reif. Die Frage ist nicht mehr ob, sondern in welcher Tiefe Banken ihre Dokumentenprozesse automatisieren.

AI Coffee Break: Alle zwei Wochenneue KI-Einblicke für Banken
Unsere Seminarreihe "AI Coffee Break" liefert alle zwei Wochenpraxisnahe Einblicke in KI-Anwendungen im Bankwesen.Jetzt anmelden und informiert bleiben!








